In the Understanding embeddings post, we covered a basic introduction to embeddings and how they are useful in many language modelling tasks such as Search, Clustering, among others. In this post, we will take a deep dive on storing the embeddings in a PostgreSQL database.
Table of Contents
Open Table of Contents
Problem statement
As the data grows in size, it is infeasible to store all the vector embeddings in memory. We need a database that can help achieve the following common goals:
- Ability to store data.
- Retrieve data efficiently.
Introduction to pgvector
pgvector is an open source Postgres library that helps in storage and retrieval of embeddings data. Here are its features:
- It can store the embeddings data along with the rest of the database
- It has inbuilt support for similarity functions such as Cosine similarity, inner product, etc.
- It supports 2 index types, which help in optimizing the data retrieval.
Installation, usage
The Github page for pgvector already covers installation and usage in detail, so I will be covering them in brief here, but for more details, I recommend visiting their Github page.
Enabling the pgvector
-- Enable the pgvector extension. required only the first time;
CREATE EXTENSION vector;Creating a table for storing embeddings
To store embeddings from gte-base model, where embedding vector is of 768 dimensional, we can define a table like below:
CREATE TABLE embeddings (
id bigserial primary key,
-- Other columns
embedding vector(768)
);Search (Cosine similarity)
pgvector provides multiple distance functions, including the cosine distance. The designated operator for this is <=> . To derive the cosine similarity (a measure of similarity between two embeddings), subtract the resulting cosine distance from 1.
SELECT
id, 1 - (embedding <=> '[3,1,....2]') AS cosine_similarity
FROM embeddings;Indexing
The rest of this post focuses on indexing and how it makes the queries faster.
PgVector provides 2 types of indexes (Link), they are:
Index creation
We will be adding an hnsw index on embeddings column for the cosine distance function, as shown below:
CREATE INDEX ON embeddings USING hnsw (embedding vector_cosine_ops);
NOTE: The index creation may take a long time depending on the memory and CPU of the database instance. After a while the index creation may also raise a warning that index computation is slow because of memory constraints.
Speeding up the index creation by allocating more memory
As highlighted above, the index creation may take a long time due to memory constraints. This is because Postgres defines a configuration parameter called maintenance_work_mem that controls maximum amount of memory that can be used for maintenance activities such as Index creation, vacuum jobs, etc.
One workaround for this problem is to allocate higher memory for the current session where we’re creating index by running:
SET maintenance_work_mem TO '512MB';
NOTE: Although the above operation helps speed up the index creation, it consumes more memory. Use it with caution in your production database servers.
Performance benchmarking of queries
We will compare the performance cosine distance operations with and without indexes. We will be using hnsw index since it has better query performance compared to IVFFlat (Ref).
Setup
We will create a table called embeddings and populate it with 339k rows in total. Each embedding column is a 768 dimensional vector (Note that I am using the gte-base model which produces 768 dimensional vectors).
select count(1) from embeddings;
count
--------
339531
(1 row)We will be using the following query to measure the performance of indexing.
EXPLAIN ANALYZE
SELECT
id,
(embedding <=> '[0.004651131108403206, -0.00583600765094161, .... 768 dimensional vector]') as cosine_distance
from
embeddings
order by
cosine_distance
limit 5Querying without indexes
We will run the above query without adding any index and capture the explain analyze output:
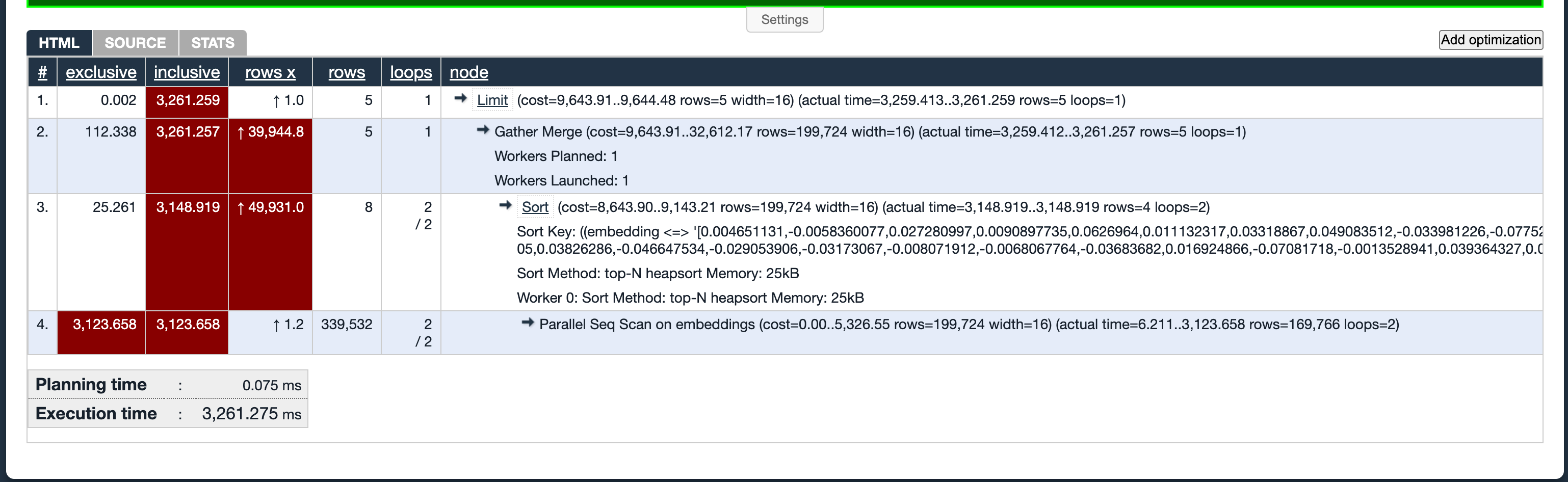
It takes about 3200ms or 3.2seconds for the query to finish.
As you can see, the above query is not suitable since it’s doing a sequential scan on the entire dataset (line number 4 in above image). We can use the index to speed up the query.
Querying with indexes
After adding the hnsw index as mentioned above, we can check the query performance again by running explain analyze, here is the result:
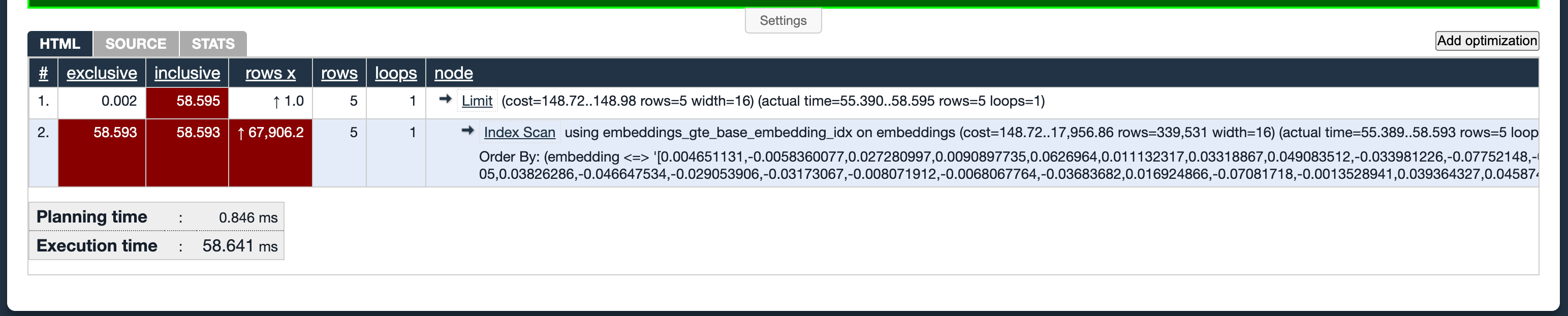
It takes only 58ms!. A 55x speedup!
Conclusion
PostgreSQL combined with pgvector is a powerful vector database that offers an easy interface to get started, and is built on top of one of the most popular databases, it also offers faster reads via indexes. Using pgvector provides simplicity and scale without the need of another infra component for your AI stack.